集合和概率
这里以一个抛硬币的试验为例引出基本概念。一个硬币有\(\{ H, T \}\)正反两面,每次得到正面的概率为0.5。共抛2次,会出现如下4种可能结果,每种概率为\(\frac14\)
1 | {H H} {H T} {T H} {T T} |
这四种可能称为全集\(\Omega\),其中每一种称为一个元素\(\omega\),这是我们关注的最小单位。\(\{ \omega \}\)是包含该元素的集合。注意:单独的\(H\)和\(T\)只是试验结果,单独出现在这里没有意义。
(为了防止大括号很乱,下文将{H H} {H T} {T H} {T T}分别记为\(\omega_1,\omega_2,\omega_3,\omega_4\)。)
假设硬币正面记为1反面记为0,我们要关注两次抛掷得到的数字相加的结果,有三种可能
1 | {w1} 2 0.25 |
这里每一种可能称为一个事件,如\(A=\{ \omega_1 \}\);事件的集合用花体字母表示,如\(\mathcal{A}=\{ \{ \omega_1 \}, \{ \omega_2,\omega_3 \} \}\)。
0 1 2是随机变量\(X\)的三种取值,随机变量的相关内容下一节再详细说明。
0.25 0.5 0.25分别是三个事件的概率,\(P(A)=0.25\)。概率\(P\)是定义在事件上而不是元素上的,因为事件是我们要关注的东西。多个不相交事件组合的概率就是单个事件概率相加。
概率\(P\)在定义时,必须保证对所有事件及组合都有效。这时就要引入域(field)的概念。域是集合的集合,里面集合的交并补等运算后的集合仍在这个域里。\((\Omega, \mathcal{B}, P)\)构成一个概率空间。其中
- \(\Omega\)就是全集\(\{\omega_1,\omega_2,\omega_3,\omega_4\}\),表示试验所有可能结果的集合,每个结果之间互斥
- \(\mathcal{B}\)是\(\sigma-field\),表示\(\Omega\) 的所有子集组成的集合。以上面的\(\Omega\)为例,它有\(2^4=16\)个子集
1 | {} 1 |
由这些子集构成的集合就是\(\mathcal{B}\)。\(P\)要对\(\mathcal{B}\)中的所有集合都有效,则由域的封闭性可知,这些集合的各种运算也都可以用\(P\)来测量。
域是可以通过更小的集合,结合交并补的运算生成的,比如通过{ {w1}, {w2}, {w3}, {w4} }就可以生成上面的所有16个集合。而如果以这个事件集合{ {w1}, {w2,w3}, {w4} }来生成域,得到的会是\(2^3=8\)种。
1 | {} 1 |
这些集合构成的域假设记为\(\mathcal{B_0}\),它是\(\mathcal{B}\)的一部分。这部分先说这么多,后面会与随机变量相联系。
随机变量
上文提到0 1 2是随机变量\(X\)的三种取值,而我们关注“数字加和”这样的规则就是随机变量。因此随机变量的本质是一个函数,一个映射,将从事件空间映射到实数空间。
我们通常说的“随机变量的值”,甚至直接用等号\(P(X=1)\),常常会让我们误以为随机变量是一个数。但随机变量是一个函数而不是一个数,随机变量取值指的是映射到的实数空间中的取值。就像我们初中学函数时\(y = f(x)\),函数\(f\)的取值是作用在某个\(x\)之后的\(y\)的取值。
随即变量取值的概率。本来概率只存在于事件空间,有了这种映射,则概率可以作用于实数空间。原来我们会说某一个事件发生的概率是多大,现在我们可以说随机变量取值为\(1\)的概率是多大。随机变量取值的概率值就是映射回事件空间中对应事件的概率。
\[ P(X\lt2)=P(\{ \omega_1,\omega_2,\omega_3 \})=0.75 \]
更严格一点应该这么写
\[ P[X<2]=P[X\in(-\infty, 2)]= P\circ X^{-1}((-\infty, 2))=P(\{ \omega_1,\omega_2,\omega_3 \})=0.75 \]
其中第二个式子表示将\((-\infty, 2)\)逆回事件空间,再用\(P\)进行测量,等价于\(P(X^{-1}((-\infty, 2)))\)。
而像\([X=1]\),\([X<2]\)这样的符号其实不符合这些字母本身的定义,只是被定义成了这样
\[ [X\in A']:=X^{-1}(A')=\{ \omega:X(\omega)\in A' \} \]
\(P\)定义时也只是能对事件进行测量,所以也只有这样逆回去,前面的\(P\)才符合定义。
接下来,我们将随机变量与域联系起来。
首先要明确,随机变量与事件是对应的。随机变量是一个函数,是将集合映射到实数空间的一种规则,确定一种规则,则确定了一组事件。考虑下面两种规则
- 关注两次抛掷得到的数字相加的结果
- 关注两次抛掷得到的数字相减的结果(第二次减去第一次)
两种规则会得到不一样的事件
1 | 相加 | 相减 |
这里定义了两个相互独立的随机变量。随机变量其实就是对全集内的元素划分组别的方式。划分出来的每一个组构成一个事件,将概率测度\(P\)定义在这些事件上,则由这些事件生成的\(\sigma-field\)中的集合都可以用\(P\)来测量。两种事件生成的域都是由全集\(\Omega\)生成的域的子集。可以看出,事件就像将几个元素分组捆绑在一起,要进行任何操作都只能针对整个组,而不能处理更细节的单个元素。举个例子,相加情况下可以测量\(\{ \omega_1,\omega_2,\omega_3 \}\)的概率;而相减情况下就不能,因为相减情况下\(\omega_1\)和\(\omega_4\)必须一起算入或排除。
期望
上面我们对随机变量的解读,只是关注它如何对全集进行划分,并没有关注划分之后的每个事件映射到实数空间中的取值。其实相同的划分可以有不同的取值,这样也对应了不同的随机变量。对这些取值以概率进行加权平均,可以得到期望。有限离散情形下定义如下
\[ E(X)=\int Xd P:=\sum_{i=1}^k a_iP(A_i) \]
对于更一般的形式,则是通过极限逼近、正部负部来定义
\[ E(X):=\lim_{n\rightarrow\infty} E(X_n) \]
\[ E(X):=E(X^+)+E(X^-) \]
需要注意的是,这里都是\(:=\)定义符号,不是说左边可以被证明等于右边,而是左边原本是没有定义的,它的定义就是通过右边进行的逼近或计算。只是后来又证明了用右边的逼近方法算和我们日常使用的积分等方法得到的结果相等,所以我们才会直接使用积分的工具计算结果,忽略它是如何被定义来的。用积分计算的方式会在下一节进行说明。
分布函数
分布函数的定义
\[ F(x):=F((-\infty, x])=P[X\leq x], x\in \mathbb{R} \]
如此一来,期望可以写成另一种形式
\[ E(X)=\int_\Omega X dP=\int_\Omega X(\omega) P(d\omega)=\int_{\mathbb{R}} x F(dx) \]
其中\(F=P\circ X^{-1}\)
积分说明
在这里需要说明一下,看到\(\int_\Omega f(\omega)\mu(d\omega)\)这种形式该如何理解,这个公式是按照下面几个步骤进行计算的
- 看在\(\Omega\)中的元素,对应到\(f(\omega)\)上有哪些种取值
- 对每一种取值,都用\(\mu\)测度测量一下该取值对应\(\Omega\)中集合的大小,将结果与\(f(\omega)\)相乘
- 对所有\(f(\omega)\)取值计算出的结果求和
举一个最简单的例子:\(\int_\Omega \sum_{i=1}^n a_i 1_{A_i}dP\)的计算过程
- 共有\(a_1\)到\(a_n\)共\(n\)种取值
- 以\(a_1\)为例,它对应的集合是\(A_1\),用\(P\)测量\(A_1\)大小,得到\(P(A_1)\),相乘得到\(a_1P(A_1)\)
- 加总得到\(\sum_{i=1}^n a_iP(A_i)\)
这就是Lebesgue积分的计算思路,根据\(y\)取值的不同测量\(x\)长度再相乘。而黎曼积分则是对\(x\)划分矩形再找\(y\)的值。需要注意的是,这里的测度\(\mu\)不一定是Lebesgue测度,它可以使概率测度、counting测度等,这些在本文中都会涉及。
这样来看上面的期望形式就很好理解了,只是从原来的关注事件空间,转化成了关注实数空间。
Transformation
在平常的计算中,有一个公式非常有趣:现有\(X, Y\)两个随机变量,它们之间的关系是\(Y=g\circ X\),则有\(E(Y)=E(g(X))\),展开成计算形式
\[ \int y F_Y(dy)=E(Y)=E(g(X))=\int g(x) F_X(dx) \]
也就是说我们要算\(Y\)的期望时其实不需要知道\(Y\)的分布,只需要用\(X\)的信息来算即可。
第一个等号已由上文说明,其中\(F_Y=P\circ Y^{-1}=P\circ (g\circ X)^{-1}=P\circ X^{-1}\circ g^{-1}\)。
第二个等号换一种形式来写会更清楚
\[ \int_\Omega Y(\omega) P(d\omega)=\int_\Omega g(X(\omega)) P(d\omega) \]
可以看出二者显然相等。
对于第三个等号,\(F_X=P\circ X^{-1}\)。
直观理解:如果认为映射空间分为三层,第一层是\(\Omega\),第二层是\(X\)作用后的\(\mathbb{R_1}\),第三层是再由\(g\)作用后的\(\mathbb{R_2}\)。目标都是要算第三层的值和对应概率。值都是第三层的值,\(\int g\circ X P(d\omega)\)是使用第一层的概率测度,\(\int y F_Y(dy)\)用的是第三层的概率测度,\(\int g(x) F_X(dx)\)则用的是第二层的概率测度。像\(\int g\circ X P(d\omega)\)用低层次的测度,就要用\(g\circ X\)计算出第三层的值。
密度函数
对于连续型变量来说,会存在一个\(f\)使得下面等式成立
\[ \int_A F(dx)=F(A)=\int_Af(x)dx \]
其中\(A\)是实数集合,\(dx\)表示Lebesgue测度,这是一个Lebesgue积分。此时\(f\)就是随机变量\(X\)的密度函数.
期望可以写成下面这种形式
\[ \int_{\mathbb{R}} x F(dx)=\int_{\mathbb{R}} xf(x) dx \]
但是如果提到离散型变量的密度函数,一般会直接用离散形式写出每个取值的概率\(P(X=k)\),对于取值区间则会用求和符号表示。如果要写成积分形式,要使用counting测度而不是Lebesgue测度。这个原因在于,将连续型变量的密度函数\(f(x)\)画在坐标系中,它下方的面积表示的就是这个区域内的概率;而离散型变量的分布函数则无法画在这样的坐标系中。举一个简单的例子,一个随机变量在\(X=0\)时概率为\(0.5\),在区间\([1,2]\)上类似均匀分布,\(f(x)=0.5\),尝试将这个密度函数画在坐标系中,我们会发现,在想要用面积表示概率时,\(X=0\)这个点没办法处理。所以离散点不能用面积来表示,而Lebesgue测度正是在算面积,因此离散点不能用Lebesgue测度来测量。
下面举一个例子,一个只在整数上有取值的分布,定义测度\(\mu\)为counting,\(p(x)\)就是这个离散变量的密度函数。
\[ \mu(A)=\sum_{k\in\mathbb{Z^d}}1_A(k), \quad p(x)=\sum_{k\in\mathbb{Z^d}} P(X=k)1_{\{ k \}}(x) \]
\[ F(A)=P(X\in A)=\sum_{k\in\mathbb{A}}P(X=k)=\int_A p(x)\mu(dx) \]
条件期望
条件期望的定义是,\(X\in L_1(\Omega, \mathcal{B}, P), \mathcal{G}\subset \mathcal{B}\),则存在随机变量\(E(X|\mathcal{G})\)是\(\mathcal{G}\) measurable and integrable,且对任意\(G\in \mathcal{G}\)都有下面式子成立
\[ \int_G XdP=\int_G E(X|\mathcal{G})dP \]
定义的的\(E(X|\mathcal{G})\)其实只是一个符号,它还有其他的写法
\[ E(X|\mathcal{G})=E(X|\sigma(Y))=E(X|Y) \]
这些都只是符号,而这个符号的本质含义是上面的那个积分。在初等概率论中,我们都知道一些条件期望的计算方式,其实只是从这个定义可以推导出那些性质,于是我们就只关注如何计算,而忽视了它本身的定义。
而看到这个定义,我们肯定想知道为什么满足这个式子就可以达到条件期望的效果,达到初等概率论中那些符合直觉的计算效果,这个式子到底是在算什么,是在让什么东西相等,这是我们接下来主要讨论的问题。
关于这个定义还有一点需要说明,\(\mathcal{G}\) measurable and integrable的意思是,\(E(X|\mathcal{G})\)这个随机变量映射回事件空间后涉及的集合,都要属于\(\mathcal{G}\)。这个条件有什么用?就是限制了要找的随机变量在子空间\(\mathcal{G}\)中,比如将\(X\)本身替换\(E(X|\mathcal{G})\)显然是满足积分那个等式的,但是因为\(X\)是定义在\(\mathcal{B}\)空间中,超出了\(\mathcal{G}\)空间的范围,所以\(X\)本身不是条件期望(只有在特定情况下是)。
条件期望计算
我们来看一个例子
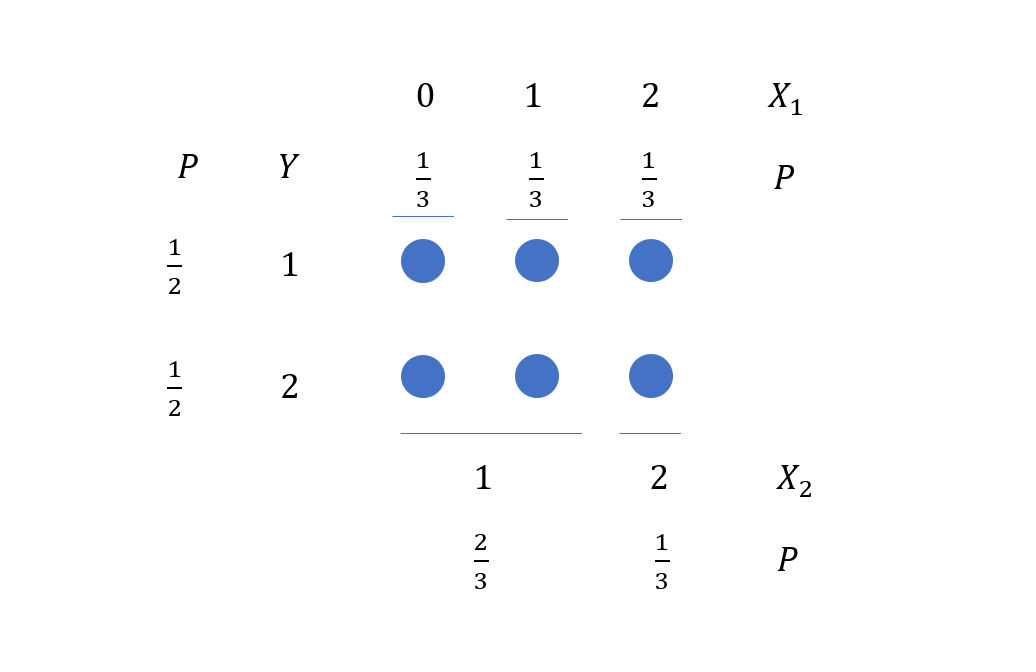
假设总共有6个球,三个随机变量在取球,\(X_1\)和\(X_2\)按列来取,\(Y\)按行来取,因此\(X_1\)和\(X_2\) 与\(Y\)独立,随机变量取值和概率如图所示。下面我们计算几个条件概率,先了解初等概率论中是如何计算的,并对变量独立有一个直观的感受。
- 计算\(E(X_1|Y)\)
\[ E(X_1|Y=1)=\frac13\times(0+1+2)=1 \]
\[ E(X_1|Y=2)=\frac13\times(0+1+2)=1 \]
\[ E(X_1|Y)=E(X_1)=\frac13\times(0+1+2)=1 \]
出现这样的结果是因为\(X_1\)与\(Y\)独立。
因此\(E(X_1|Y)\)是这样一个随机变量(即常数\(E(X_1)\)):可以取一个值\(1\),概率为\(1\).
- 计算\(E(X_1|X_2)\)
\[ E(X_1|X_2=1)=\frac12\times(0+1)=\frac12 \]
\[ E(X_1|X_2=2)=1\times 2=2 \]
\[ P(X_2=1)=\frac23,\quad P(X_2=2)=\frac13 \]
因此\(E(X_1|X_2)\)是这样一个随机变量:可以取两个值\(\frac12\)和\(2\),概率分别为\(\frac23\)和\(\frac13\).
所以\(E(E(X_1|X_2))=E(X_1)=1\)
- 计算\(E(X_1|X_2, Y)\)
\[ E(X_1|X_2=1, Y=1)=\frac12\times(0+1)=\frac12 \]
\[ E(X_1|X_2=2, Y=1)=1\times 2=2 \]
\[ E(X_1|X_2=1, Y=2)=\frac12\times(0+1)=\frac12 \]
\[ E(X_1|X_2=2, Y=2)=1\times 2=2 \]
\[ P(X_2=1, Y=1)=\frac13,\quad P(X_2=2, Y=1)=\frac16 \]
\[ P(X_2=1, Y=2)=\frac13,\quad P(X_2=2, Y=2)=\frac16 \]
可以看到\(E(X_1|X_2, Y)\)的取值可以合并,最后结果和\(E(X_1|X_2)\)相同,即\(E(X_1|X_2, Y)=E(X_1|X_2)\)。
这里可以对独立在条件期望中的作用有一个直观的感受,因为\(Y\)与\(X_1\)独立,因此无论\(Y\)取什么值都不影响\(X_1\)的取值。
理解定义
下面我们关注这个式子
\[ \int_G X_1dP=\int_G E(X_1|X_2)dP \]
将具体数值带进去,假设\(G\)指\(X_2=1\),应用上一章中对积分的解读计算这两个积分
- 对于\(\int_G E(X_1|X_2)dP\),在\(G\)这个区域内,\(E(X_1|X_2)\)只取一个值\(\frac12=\frac12\times(0+1)\),乘以\(G\)发生的概率\(\frac23\),得到结果为\(\frac13\)
- 对于\(\int_G X_1dP\),在\(G\)这个区域内,\(X_1\)可以取两个值\(0\)和\(1\),它们的概率都是\(\frac13\),所以得到结果为\(\frac13\times(0+1)=\frac13\)
因此这个公式大概是说,在子空间中得到的期望,乘以子空间发生的概率,要等于直接在全空间中计算子空间的期望。